 Tanmoy Chakraborty
is a postdoctoral researcher at University of Maryland Institute for Advanced Computer Studies. He obtained his PhD in the area of data mining and social network analysis from Indian Institute of Technology, Kharagpur (IIT-Kgp). His research interests are in the broad areas of data mining, complex networks, social media, natural language processing, cybersecurity and machine learning.
Tanmoy Chakraborty
is a postdoctoral researcher at University of Maryland Institute for Advanced Computer Studies. He obtained his PhD in the area of data mining and social network analysis from Indian Institute of Technology, Kharagpur (IIT-Kgp). His research interests are in the broad areas of data mining, complex networks, social media, natural language processing, cybersecurity and machine learning.
Tanmoy on ..
ML India: We’d like to start off by understanding your background and how you got initiated into the field of Machine Learning?
Tanmoy: During my bachelor’s, I didn’t have any idea about research. At the time, my aim was to get a job in the IT sector and be financially independent. But I realized overtime that I wanted to pursue higher studies post my bachelor’s and passed the GATE exam and joined the M.E. program at Jadavpur University. I was supervised by Prof. Sivaji Bandyopadhyay, dean of engineering programs and head of the computer science department. He is one of the early NLP researchers in India. It was there when I started to try and understand what research actually means. Initially, I worked mostly on NLP in particular regional languages, for instance, identifying different idioms and various expressions from Bengali literature. I also worked on identifying stylistic writing patterns of different writers where we wanted to identify the author of an unknown doc using the Stylometric analysis. This really fascinated me. Prof Sivaji offered me to join his PhD group but I wanted better environment and resources to pursue my PhD and so I joined IIT Kharagpur in Dec 2011 as a PhD candidate. However, I wasn’t sure about the particular domain I will be working in and was pretty open minded. Since I had some experience in NLP, I wanted to work in related fields like Information Retrieval, ML etc. The research coordinator there suggested me to join the Complex Network Research group with Prof. Animesh Mukherjee and Prof. Niloy Ganguly. This group has been one of the well-known groups in India in the area of social network analysis. I also realised that the research conducted by this group (dealing with graph theory, data mining, text processing) was highly aligned to my interest. I also won the Google India Phd fellowship within 6 months of my joining which motivated me a lot. So I started research on complex networks. In the third year, I got an internship at IBM Research Bangalore where I worked with Dr. Ramasuri Narayanam and I was able to publish 2 top tier papers in the three and a half month duration. This was how I paved my path into the Machine Learning space.
ML India: Can you elaborate a bit about your PhD project, the problem statement and the state of the art?
Tanmoy: I was focusing on two aspects during the project. One was community analysis in large networks. It can be related to clusters in data mining. The highly interconnected nodes in a network are called as clusters or communities. For instance, if you have a facebook network where nodes are the users and links are the friend relations, the task was to find dense groups from the network. ‘Community’ is not a very well defined term. There is no threshold to call a group of nodes a community. What’s interesting is that all the existing algorithms that are trying to identify communities are pretty much dependent on vertex ordering. For the same network, starting with a vertex ‘A’, for instance, will result in a completely different community structure than the one which is defined if we start at some other vertex ‘B’. So we started working on why these algorithms are dependent on vertex ordering. We also started working on finding invariant stable community structures which are independent of any vertex ordering and algorithms. We named these groups as “constant communities”. So we proposed a new definition to communities and also defined a metric called ‘Permanence’. This opposed the ‘Modularity’ metric’s notion that nodes should be densely connected within a network and sparsely connected across networks. Permanence identified communities by measuring the distribution of external neighbors in other networks. An uneven distribution would mean more pull from one network and hence higher chances of migration. This part of the research was conducted in collaboration with Prof. Sanjukta Bhowmick, University of Nebraska, Omaha.The other part I was focusing on is another type of complex network called the Citation Network. We considered scientific articles and papers as nodes/vertices of these networks and links as the citations. This is a directed network which generates a link to other referred papers in a particular paper. Since the data set wasn’t freely available, we crawled the publication dataset from Microsoft Academic Search and collected around 80 million papers. So we analyzed and studied the evolution and paradigm shifts in the field of computer science. We wanted to quantify the inter-disciplinarity of the research since all these fields are interrelated and we wanted to measure this parameter. We then tried to model the evolution of a new field by cross hybridization of different other fields. This is some of the work that I have done earlier.
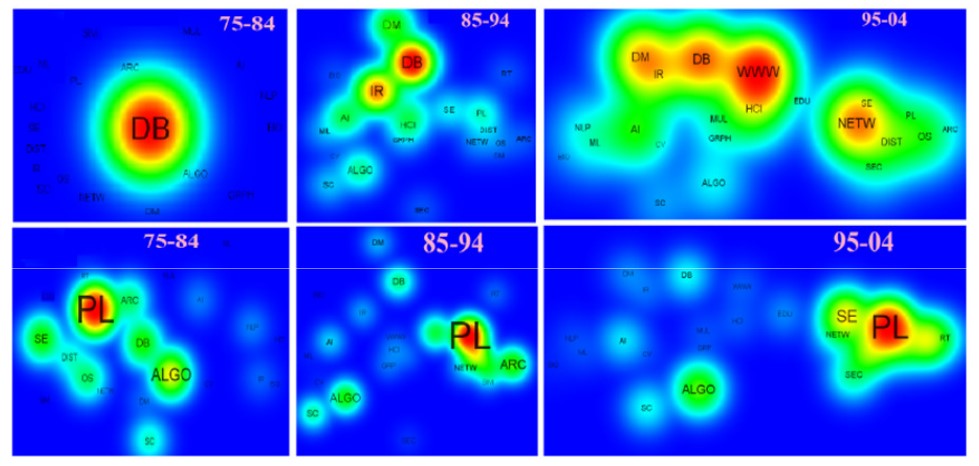
We also built the evolutionary landscape which suggests the evolution of different topics over time. It shows the connection proximity within the topics and then it shows the relative importance of a field during a time period. We tried to visualize the growing topics in the field of computer science over the years (as shown in the fig. below). For reference, PL refers to programming language, DB refers to database, SE to software engineering and so on. So, here we can see that PL has been a prominent topic over the years but the distance between PL and Algo has increased over the last two decades from which we can infer that over the years Algo has also becomes so much dense in itself that it has evolved as a separate and a larger topic. I did a lot of other work as well around citation network which you can visit on my dissertation ppt. In the other work, by the help of the existing information about different papers and their citations over the years we can predict the citations, after 5 years, for a newly published paper. Further we built a system to produce “faceted recommendation” for scientific articles. My thesis got Xerox India Best Thesis Award, 2016.
 [Top]
[Top]
ML-India: What are the research problems that you’re working on at the University of Maryland?
Tanmoy: Currently I am working in the Laboratory of Computational Cultural Dynamics (CCD) under the supervision of Prof. V.S. Subrahmanian. He has a strong background in Artificial Intelligence and wanted to work on an intersection of Artificial intelligence and Data Mining. I am working on two security related projects. First is related to cyber security where I’m working on predicting malwares across countries and predicting the number of malware infected machines in the next year in India. We are also trying to understand the behavioral dynamics of malware entries..
The second project involves work on devising different strategies to make an improvised network secure and safe from attackers. We are using game theory to conduct this research wherein the attacker is one player and the defender is the other. The defender needs to deploy strategies to decrease the damage. However these strategies come at a cost. So proposing these strategies while maintaining the right balance with the cost is the problem statement. Here we are using re-inforcement learning, an essential part of our project, where the attacker keeps compiling more information about the host/defender over the time period.
In parallel, I’m also working on two data mining projects. First is the network embedding problem in collaboration with UNC Charlotte. This focuses on representing a given network in a feature space. We get a lot of latent information from the network. Right now we are focusing on deep learning to represent this network in a feature space and we hope that this representation can help us increase the accuracy of different other applications like link prediction, clustering etc.
The second project is related to terrorist networks where we are analyzing terrorist behaviour of various terrorist groups. The most difficult part of this project is to collect all the data. There are 3-4 papers and some books which are available. My task is to design the prediction models to determine the “lethality” of such networks which determines how dangerous the network will be, say 1 year from now, so we can devise some defensive strategies which can decentralize these activities.
ML India: As you’ve worked in Jadavpur University, then in IIT Kharagpur and now at University of Maryland, what is the difference in the ways that the labs are performing their research and what is the general research culture?
Tanmoy: First of all, let me tell you that I am extremely fortunate to work with those groups. However, what I found at Jadavpur University is that people are not very optimistic about their research. They publish their work in small conferences due to which it doesn’t get a lot of attention. Another issue is the availability of quality resources. At IIT Kharagpur, my group had a lot of collaborations internationally which provided a lot of exposure. Being one of the leading groups, we always targeted for top conferences like SIGKDD, SIGIR, WWW etc. The problem I experienced here is the well known ‘Publish and Perish’ problem where the pressure to publish large amount of papers in a limited time is high and you might be sacrificing on the quality sometime. I feel that there is a need to spread the word that research requires time input and it’s not every time that you find success. In contrast, the infrastructure at the University of Maryland is excellent, I have access to the technology that I need to conduct my research which I didn’t have at IIT Kgp. Most importantly, the faculty here is focusing on proposing interesting problems and provides us enough time to think about the problems carefully.
ML India: What is your view on machine learning as a field of research and its growing popularity among students?
Tanmoy: I’ve never thought of Machine Learning as a separate research subject. ML has always been an integral part of my research. It’s a tool which needs to be used in various areas of research. I, being a data mining researcher, try to diagnose big data and figure out various aspects out of it. When you have to label unlabelled data using some sort of labelled data, machine learning is necessary. So ML is a very integral part of my research.One of the fundamental part of my research is the synthesis of features for ML. If you have a state of features, which are not very valuable, to represent an entity, we need ML to synthesize these features into latent usable features. This is called feature synthesis, which is what I am currently working on. I’m also working with semi supervised learning approach, which is really useful if you have labelled data as low as 1%. [Top]
ML India: How do you think can India’s participation in ML research be boosted in the global research sphere?
Tanmoy: There has been a significant growth on the Indian machine learning front over the past 5-6 years. I feel that the research needs to be more focused and that more emphasis should be put on defining the problem properly. This is very crucial in driving the research in the right direction. If you read papers from data mining guys at MIT, Stanford etc. you’ll notice that they are not coming up with any new techniques. They are crawling new data, they are proposing a very innovative problem out of the data. The methods and approach are not extra-ordinary but at the end, they get the paper published. So working on a quality problem definition is an extremely important factor in increasing the chances to showcase the research at top tier conferences and gaining wider recognition.
ML India: It was great talking you, Tanmoy. Thank you for your time and words. All the very best to you from ML-India!